
Ship LLM apps
with confidence.
LastMile is the full-stack developer platform to debug, evaluate & improve AI applications. Fine-tune custom evaluator models, set up guardrails and monitor application performance.








AutoEval
Custom metrics for your application
AutoEval enables fine-tuning blazing-fast evaluator models customized to your eval criteria.
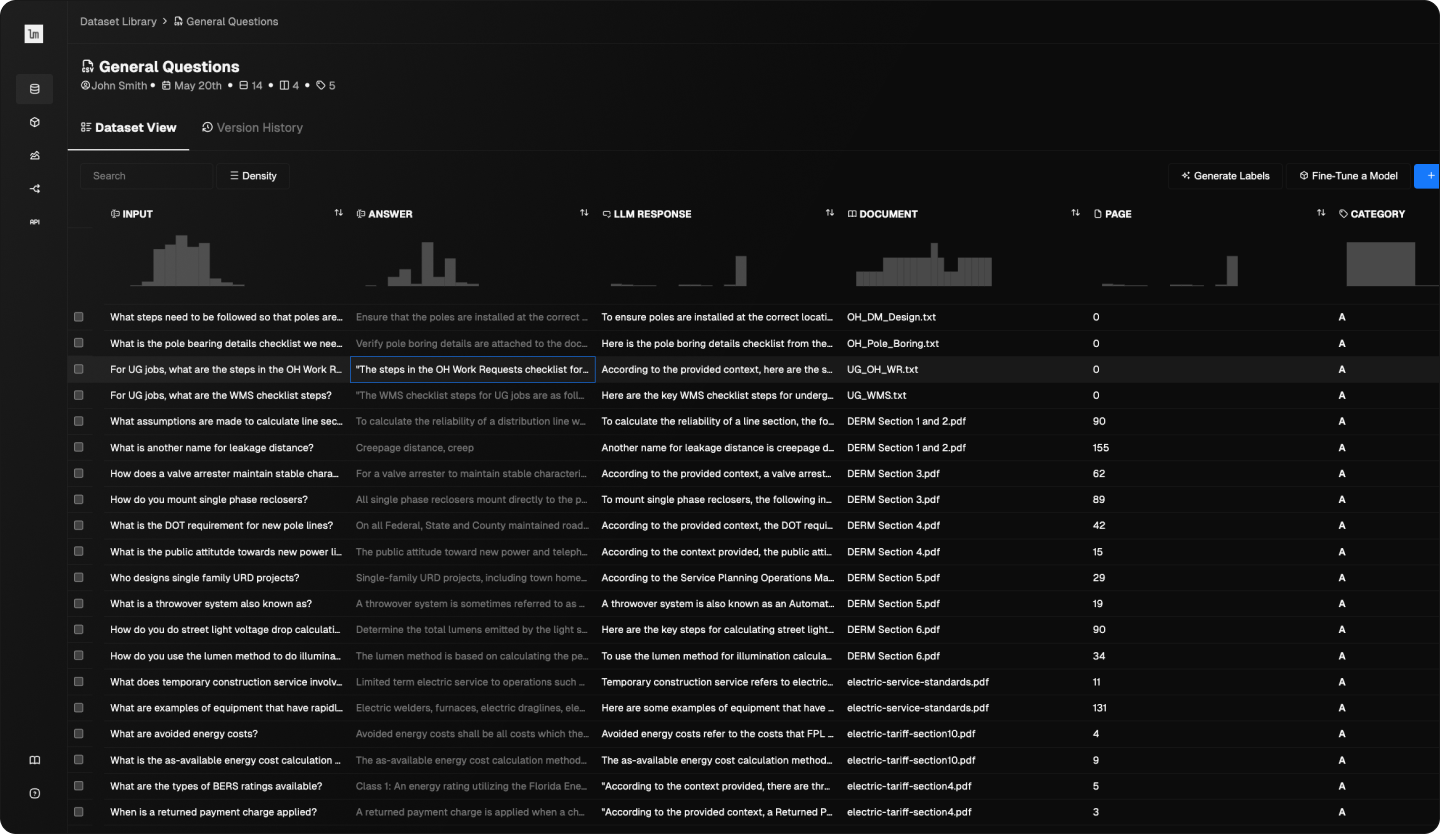
Upload & manage application data, such as input/output trace data
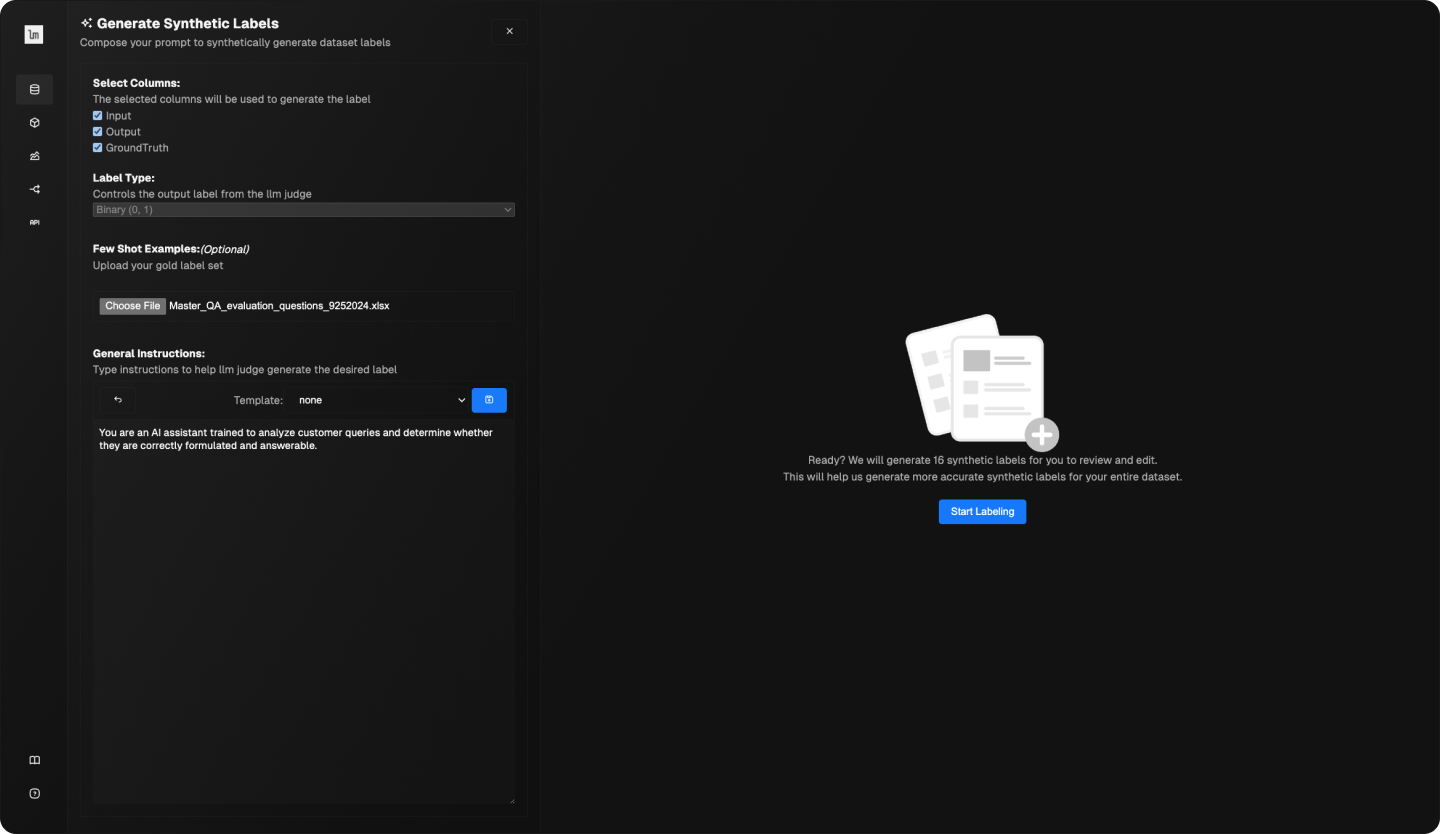
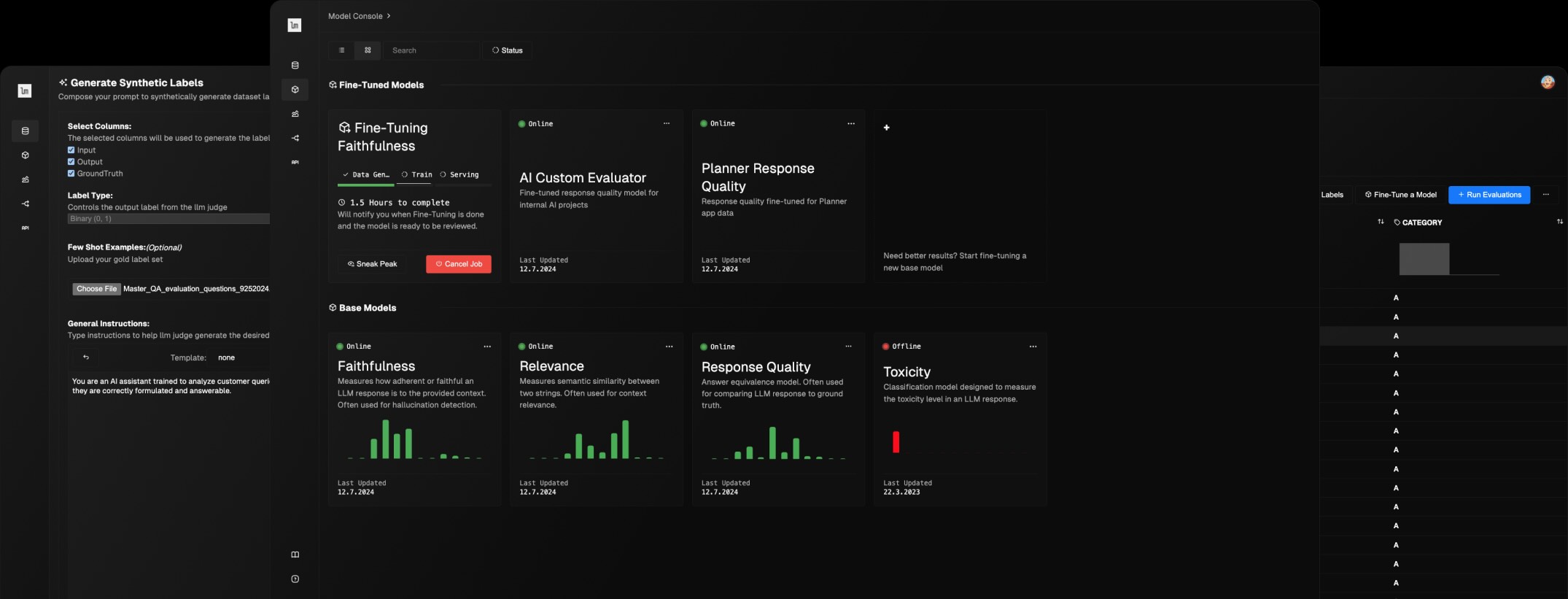
Generate synthetic labels for your application data by defining your evaluation criteria as a prompt, and labeling with LLM Judge + human-in-the-loop.
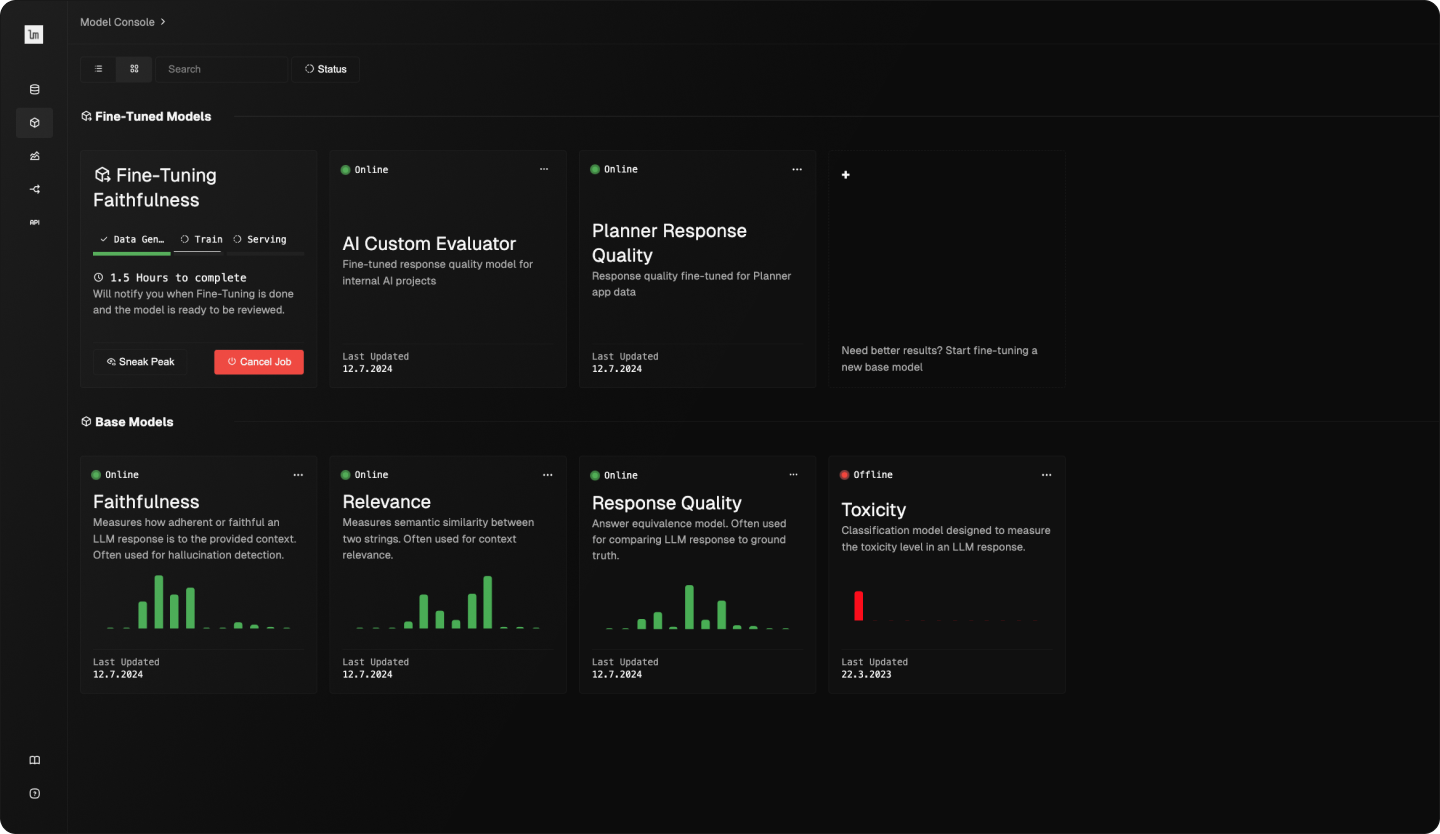
Fine-tune a small evaluator model distilled from the labeled dataset. Use this custom metric for both offline evals and online guardrails.
Eval-driven AI development
We are determined to make AI development more science than art. AutoEval comes batteries-included with evaluation metrics for RAG and multi-agent AI applications, as well as a fine-tuning service to design your own evaluators.
Answer questions like “how faithful is the LLM response to the data passed in?” or “how well does it adhere to my brand tone?”.

Meet alBERTa
A powerful small language model designed for evaluation tasks
Small-
400M params
Fast-
300ms inference
Efficient-
Runs on CPU
alBERTa is a versatile 400M parameter entailment model that generates a numeric score for evaluation tasks like faithfulness.
Its small size means it can run inference in less than 300ms, be deployed on CPU, and be fine-tuned efficiently for custom evaluation tasks.
Realtime Guardrails
Guardrails are just fast online evaluators in your app runtime. Use our evaluators for real-time checks on hallucinations, toxicity, safety, or custom criteria.
Secure & Private
Maintain complete control over your data plane by deploying the LastMile platform within your VPC.
Join the mission
Talks & Workshops:

Small Models,
Large Impact
We provide specialized small language models for discrete tasks, which you can easily personalize, fine-tune and run efficiently on your own infrastructure.